
https://blog.bytebytego.com/i/191425992/the-hidden-reality-of-ai-driven-development-sponsored

Retrieval-Augmented Generation (RAG) has become a foundational approach in modern AI systems, particularly for grounding large language models (LLMs) in external knowledge. However, as adoption has increased, so have the limitations of traditional RAG pipelines. While effective for straightforward queries, standard RAG systems often struggle with ambiguity, incomplete information, and misleading retrieval results.
Agentic RAG emerges as an evolution of this paradigm. Instead of treating retrieval as a one-time step, it introduces decision-making, iteration, and evaluation into the process. The result is a more adaptive system that behaves less like a static pipeline and more like a reasoning-driven workflow.
This article explores how Agentic RAG works, what problems it addresses, and the trade-offs that come with its added complexity.
Understanding Standard RAG: A Linear Pipeline
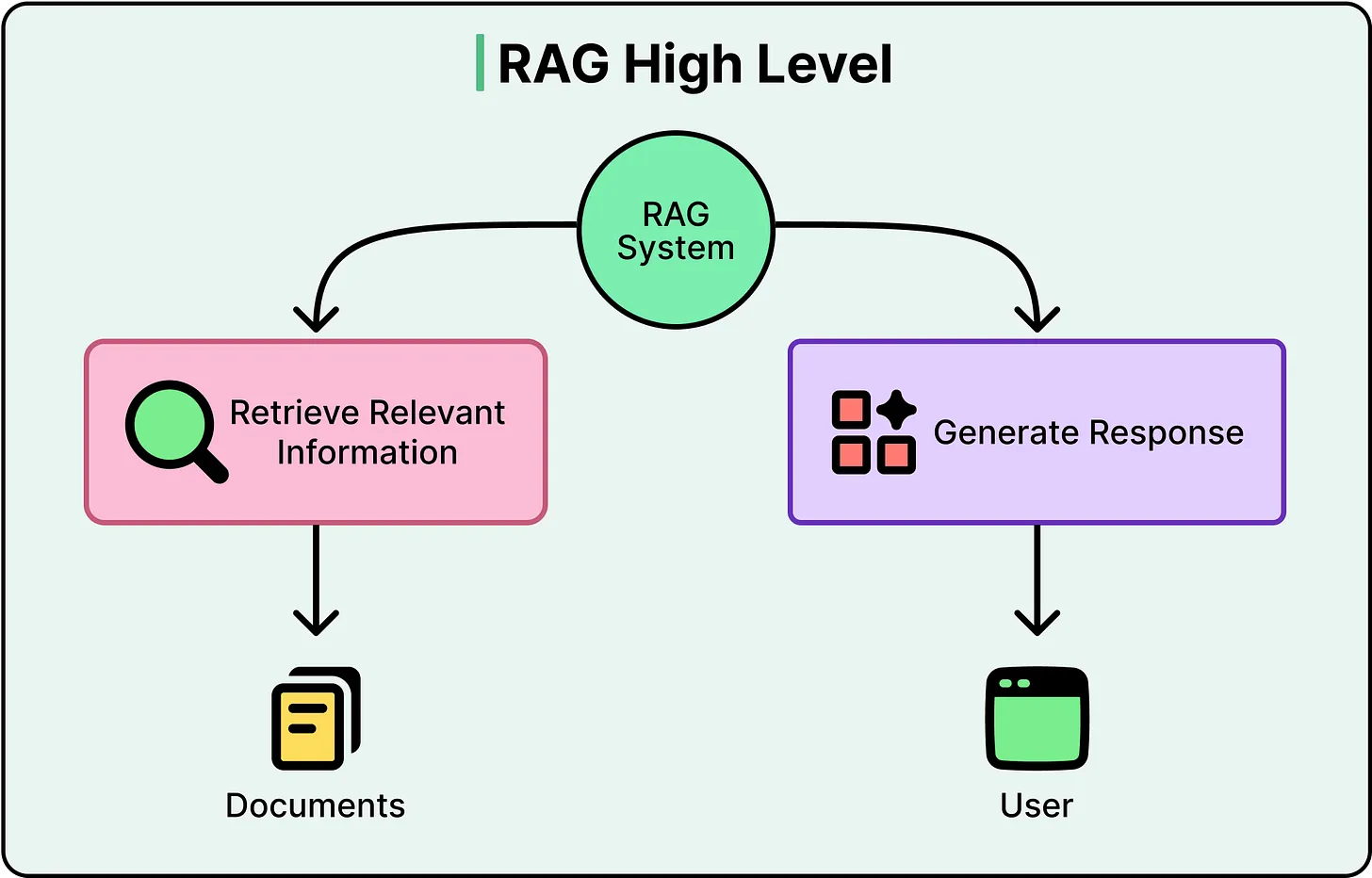
To understand Agentic RAG, it is necessary to first examine the structure of a conventional RAG system.
A typical RAG workflow follows a linear sequence:
- A user submits a query
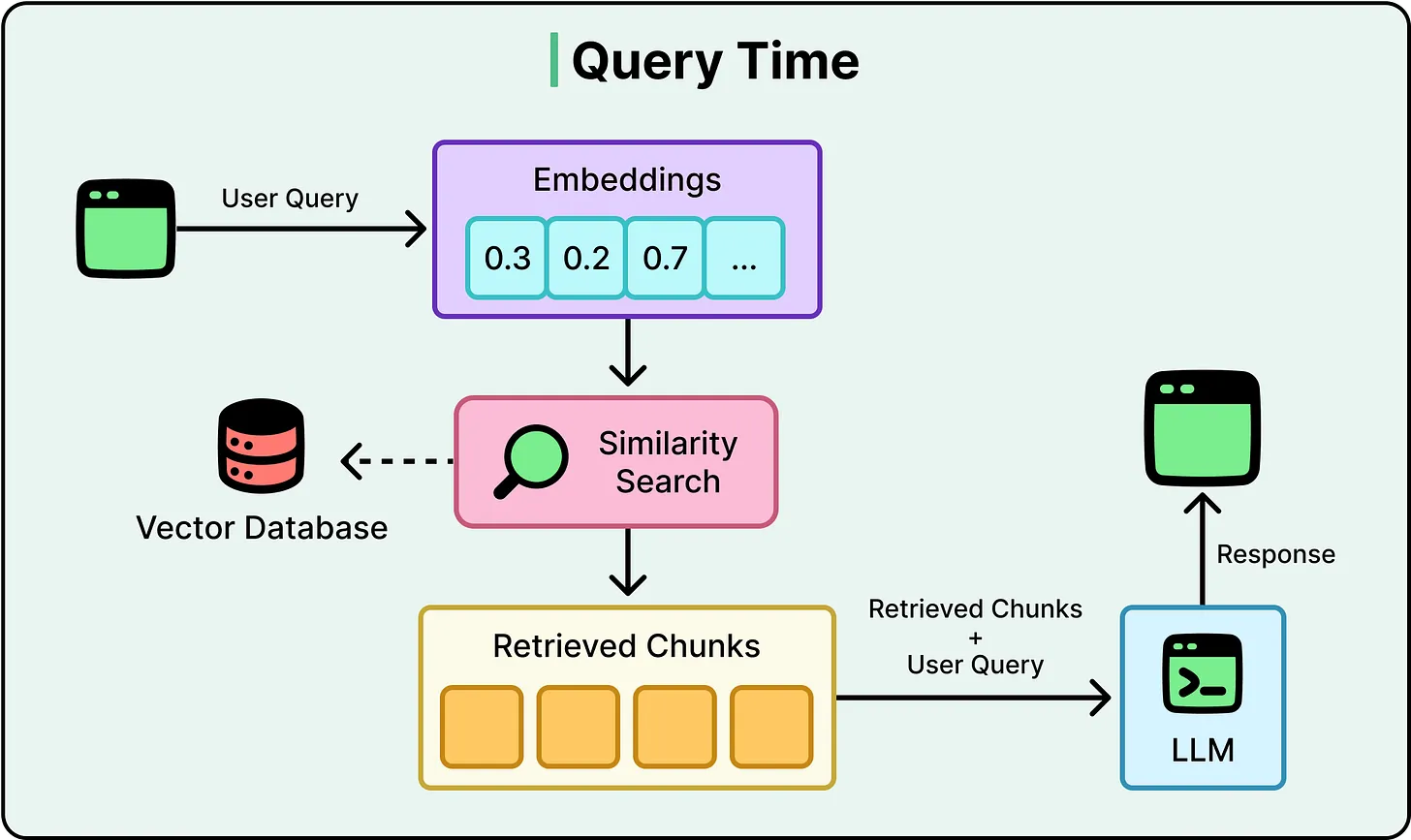
- The system converts the query into an embedding (a numerical representation of meaning)
- A vector database retrieves the most semantically similar documents
- These retrieved documents are passed to an LLM
- The LLM generates a response based on this context
This pipeline works well when:
- The query is clear and specific
- The relevant information exists in a single location
- The retrieved content accurately reflects the correct answer
However, the system has a critical limitation: it does not verify whether the retrieved information is actually sufficient or correct before generating a response.
Where Standard RAG Breaks Down
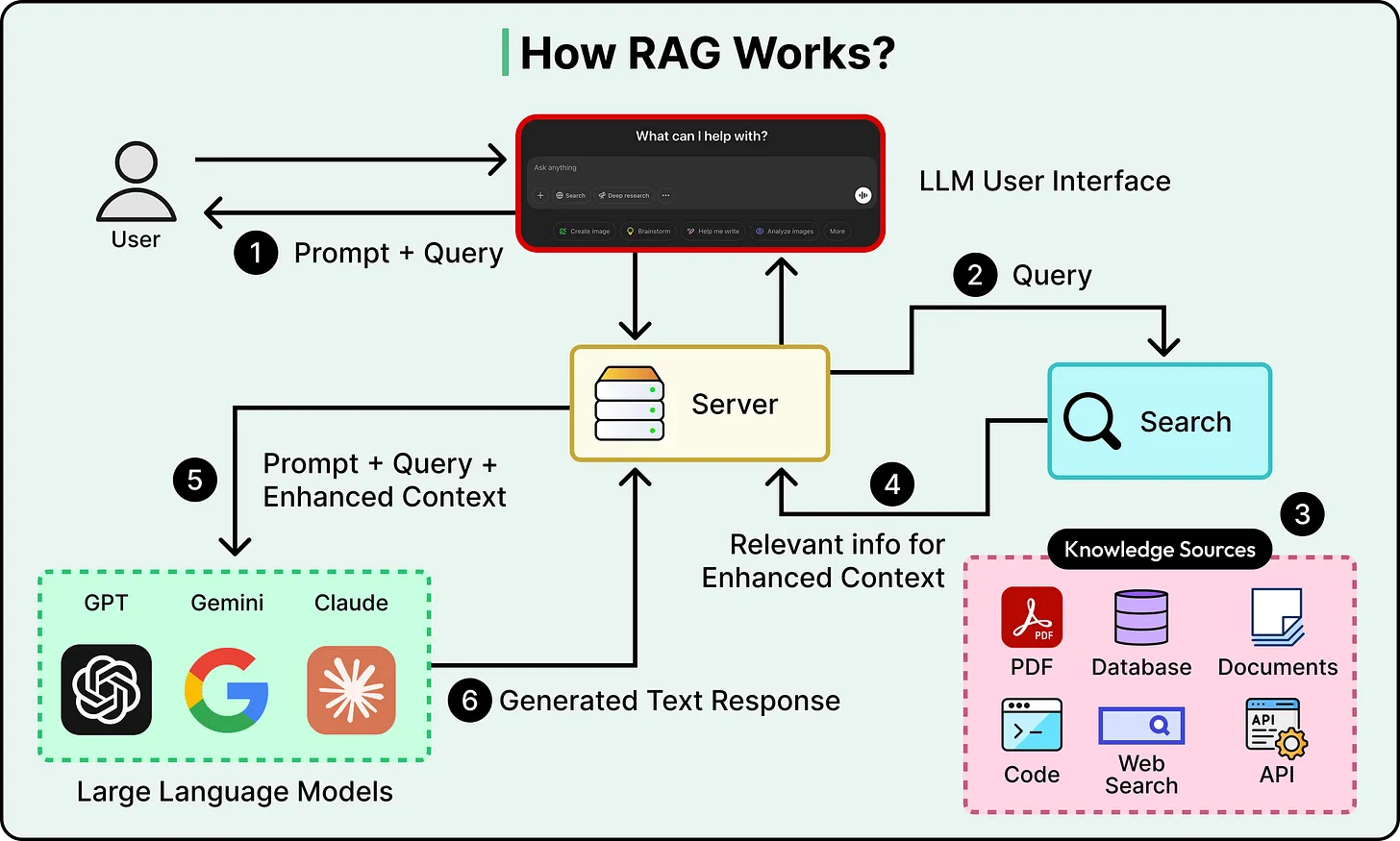
Three recurring failure patterns expose the weaknesses of this approach:
1. Ambiguous QueriesWhen a query lacks specificity, the system retrieves results based purely on similarity scores. For example, a question like “How do I handle taxes?” could refer to multiple domains—personal, corporate, or legal. Standard RAG does not clarify intent; it simply proceeds with the most likely match.
2. Fragmented InformationIn many real-world scenarios, answers are distributed across multiple documents or data sources. A linear pipeline retrieves a limited set of results and does not actively seek additional context if the initial retrieval is incomplete.
3. Misleading RelevanceSimilarity-based retrieval can return content that appears relevant but is outdated, incomplete, or contextually incorrect. Since the system lacks a validation step, it may generate confident but inaccurate responses.
These issues share a common root cause: the absence of reflection or decision-making between retrieval and generation.
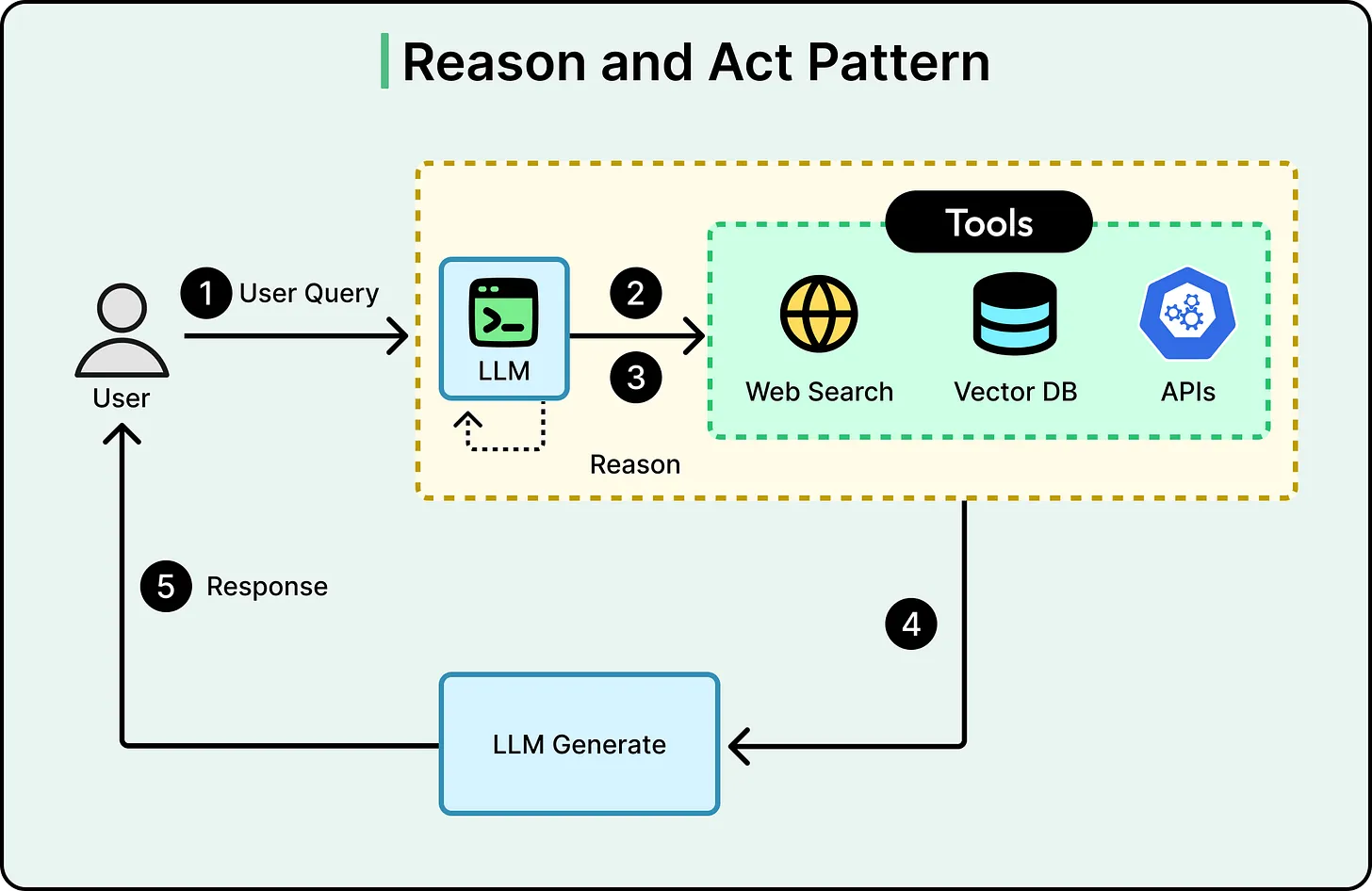
Agentic RAG: Introducing a Control Loop
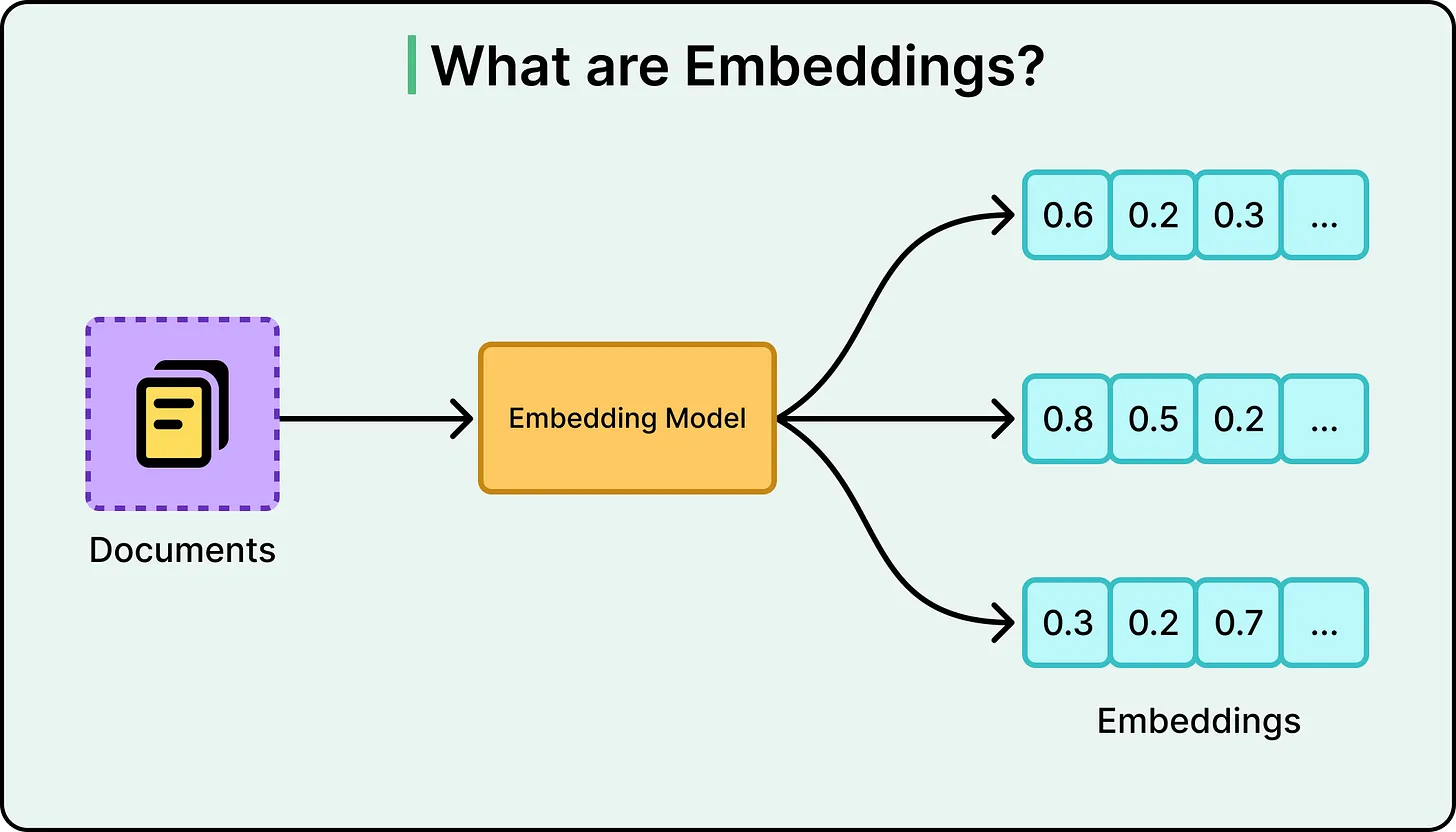
Agentic RAG addresses these limitations by transforming the static pipeline into a dynamic loop. Instead of a single retrieval step followed by generation, the system introduces intermediate reasoning stages.
The workflow becomes:
- Interpret or refine the query
- Retrieve relevant information
- Evaluate the quality and completeness of results
- Decide whether to proceed or iterate
- Repeat retrieval if necessary
- Generate the final response
This loop introduces a critical capability: the system can pause, reassess, and try again before producing an answer.
At the center of this approach is an AI agent—typically an LLM enhanced with tool-use capabilities and decision-making logic.
Core Capabilities of Agentic RAG
Before retrieval even begins, the agent can rewrite or decompose a query into more precise sub-queries. This is particularly useful when dealing with vague or multi-intent questions.
For example:
- A broad query may be split into multiple targeted searches
- Context from prior interactions can inform query interpretation
- The system can adapt its search strategy based on early results
This reduces the risk of retrieving irrelevant or incomplete data.
2. Intelligent Routing Across Data SourcesUnlike standard RAG, which typically queries a single vector database, Agentic RAG can dynamically select between multiple data sources.
These may include:
- Document stores
- Structured databases (e.g., SQL systems)
- APIs or external services
The agent determines where to search based on the nature of the query. In complex cases, it may query multiple sources sequentially and combine the results into a unified response.
This capability is especially valuable in enterprise environments where knowledge is distributed across systems.
3. Self-Evaluation and IterationPerhaps the most important feature of Agentic RAG is its ability to evaluate its own retrieval results.
After retrieving information, the agent can assess:
- Relevance: Does the content directly answer the question?
- Completeness: Is additional information required?
- Consistency: Are there contradictions across sources?
If the evaluation fails, the system can:
- Reformulate the query
- Search alternative sources
- Retry with adjusted parameters
This iterative process directly addresses the “one-shot” limitation of standard RAG.
https://blog.bytebytego.com/i/191425992/ai-companies-arent-scraping-google-sponsored

From Pipelines to Reasoning Systems
Agentic RAG is best understood as a shift from static execution to adaptive reasoning.
In its simplest form, it may function as a routing layer—choosing between a small number of data sources. More advanced implementations incorporate frameworks where the agent alternates between reasoning and action, repeatedly refining its approach.
At the highest level of sophistication, multiple agents may collaborate:
- One agent retrieves data
- Another evaluates quality
- A third synthesizes the response
An orchestrator coordinates these interactions, forming a modular and extensible system.
Addressing Core RAG Limitations
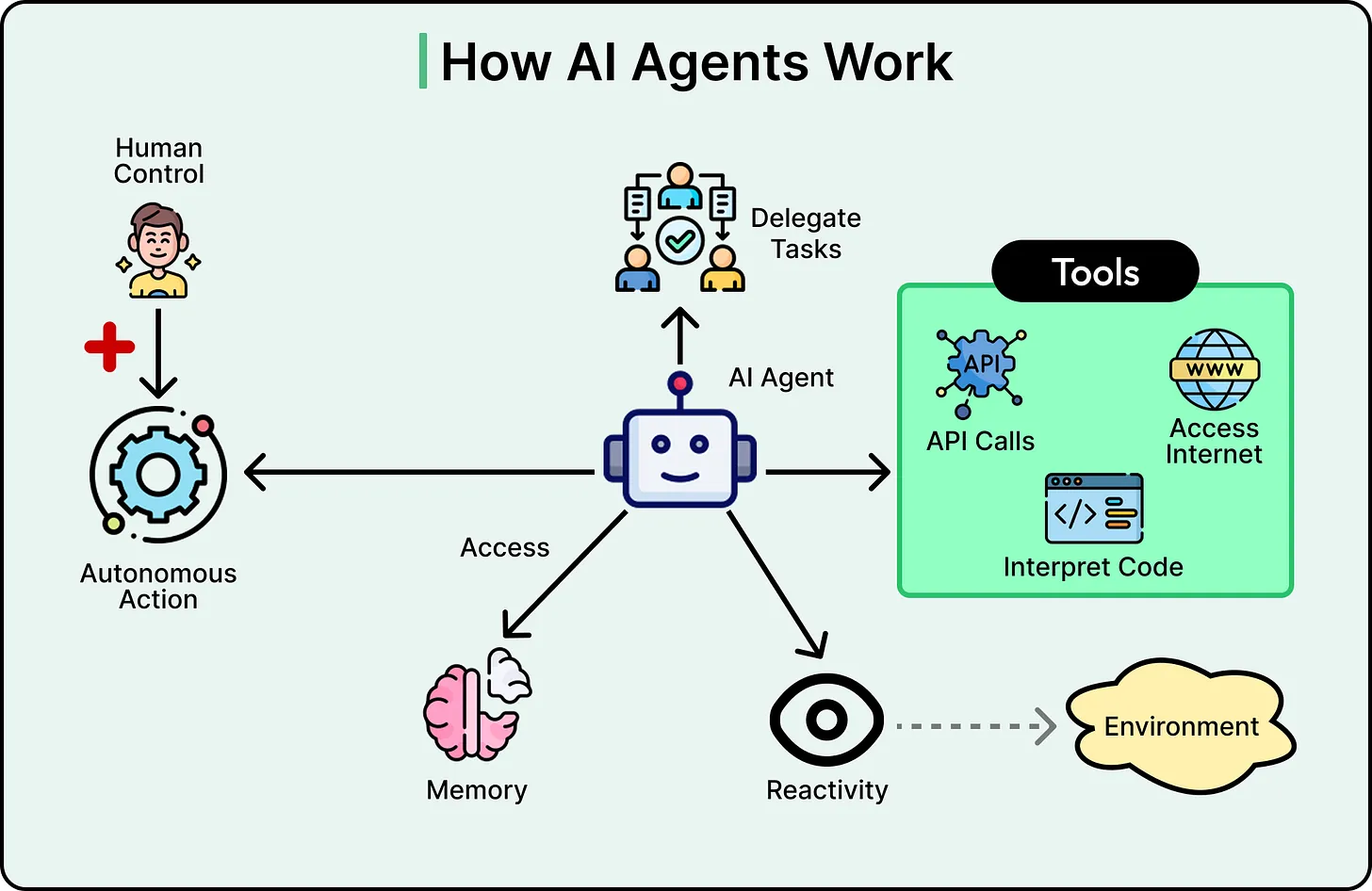
Agentic RAG directly resolves the earlier failure modes:
- Ambiguity is handled through query refinement and decomposition
- Fragmentation is addressed via multi-source retrieval and synthesis
- False confidence is reduced through evaluation and iterative correction
The system no longer assumes that the first retrieval is sufficient. Instead, it actively verifies and improves its understanding before responding.
Trade-offs and Practical Constraints
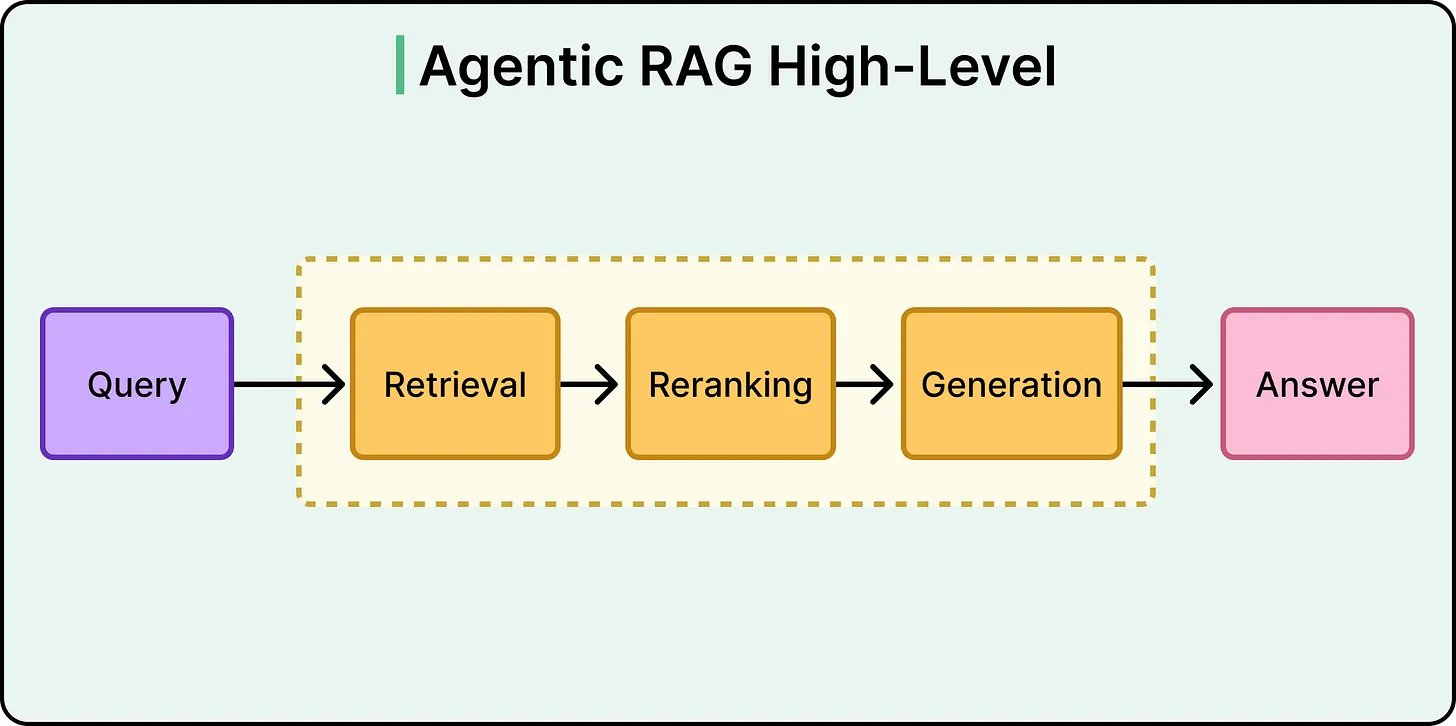
Despite its advantages, Agentic RAG is not universally superior. Its benefits come with measurable costs.
LatencyEach iteration in the loop introduces additional processing time. While a standard RAG query may complete in seconds, an agentic system can take significantly longer, especially if multiple retrieval cycles are required.
CostEvery decision, evaluation, and retrieval step consumes computational resources. At scale, this can increase operational costs substantially compared to simpler pipelines.
Complexity and DebuggingAgentic systems are inherently less predictable. Since the agent makes dynamic decisions, identical queries may follow different execution paths. This complicates testing, debugging, and performance optimization.
Evaluation Reliability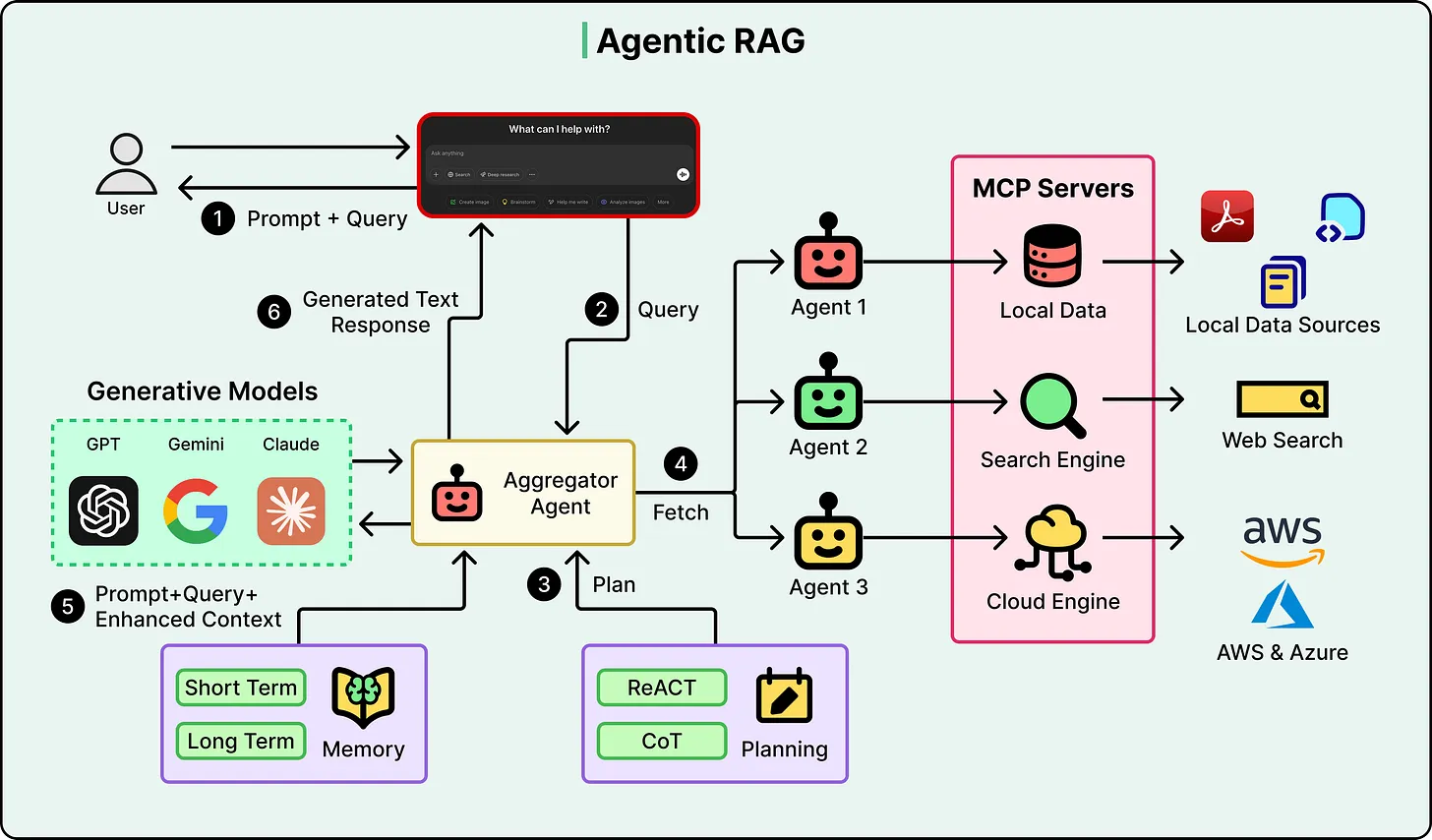
The system relies on an LLM to judge the quality of retrieved information. If this evaluation is flawed, the system may either:
- Accept poor results
- Reject valid results and over-iterate
This creates a dependency loop where one model evaluates another, introducing potential bias.
Over-IterationIn some cases, the system may continue searching unnecessarily, discarding useful results in pursuit of marginal improvements. This can degrade both performance and response quality.
When to Use Agentic RAG
Agentic RAG is most effective in scenarios where:
- Queries are complex or ambiguous
- Information is distributed across multiple sources
- Accuracy is more critical than latency
- Contextual reasoning is required
However, it may not be suitable for:
- Simple FAQ-style queries
- High-volume systems with strict latency constraints
- Well-structured, single-source knowledge bases
In many cases, improving data quality or retrieval mechanisms may yield better results than introducing agentic complexity.
Conclusion
Agentic RAG represents a significant shift in how AI systems interact with external knowledge. By introducing a feedback loop with decision-making capabilities, it transforms retrieval from a static step into an adaptive process.
The key insight is straightforward: the value of Agentic RAG lies in its ability to question its own outputs before responding.
Rather than assuming that the first retrieved result is correct, the system evaluates, refines, and iterates until it reaches a more reliable answer. This makes it particularly suited for complex, real-world applications where ambiguity and incomplete information are the norm.
However, this added intelligence comes at the cost of latency, complexity, and operational overhead. As a result, adopting Agentic RAG should be a deliberate engineering decision, not a default upgrade.
Ultimately, the choice between standard and agentic RAG depends on a single question: Does the problem require reasoning, or just retrieval?

