
https://blog.bytebytego.com/i/192334405/openclaw-you-can-trust-sponsored

In today’s globally connected digital environments, real-time communication across languages is no longer a luxury—it is a necessity. Platforms with massive, diverse user bases must solve translation not only accurately, but instantly. Roblox, a platform hosting tens of millions of daily users interacting across hundreds of countries, has engineered a translation system that operates at remarkable scale and speed. Their approach reflects a series of deliberate architectural and operational trade-offs designed to balance quality, latency, and scalability.
This article examines how Roblox built a unified AI-driven translation system capable of handling 16 languages—covering 256 translation directions—in approximately 100 milliseconds per request, while processing thousands of messages per second.
The Challenge of Multilingual Scale
Supporting 16 languages is not a simple linear problem. Each language must be translated into every other language, resulting in 256 possible translation pairs. A straightforward approach would involve building a separate model for each pair. However, this strategy quickly becomes impractical.
Maintaining hundreds of models introduces significant overhead:
- Separate training pipelines for each pair
- Increased infrastructure complexity
- Continuous maintenance and updates
- Exponential growth when adding new languages
Roblox recognized early that this model-per-pair strategy would not scale effectively. Instead, they adopted a unified model approach—one system capable of handling all translation directions simultaneously.
A Unified Model with Mixture of Experts
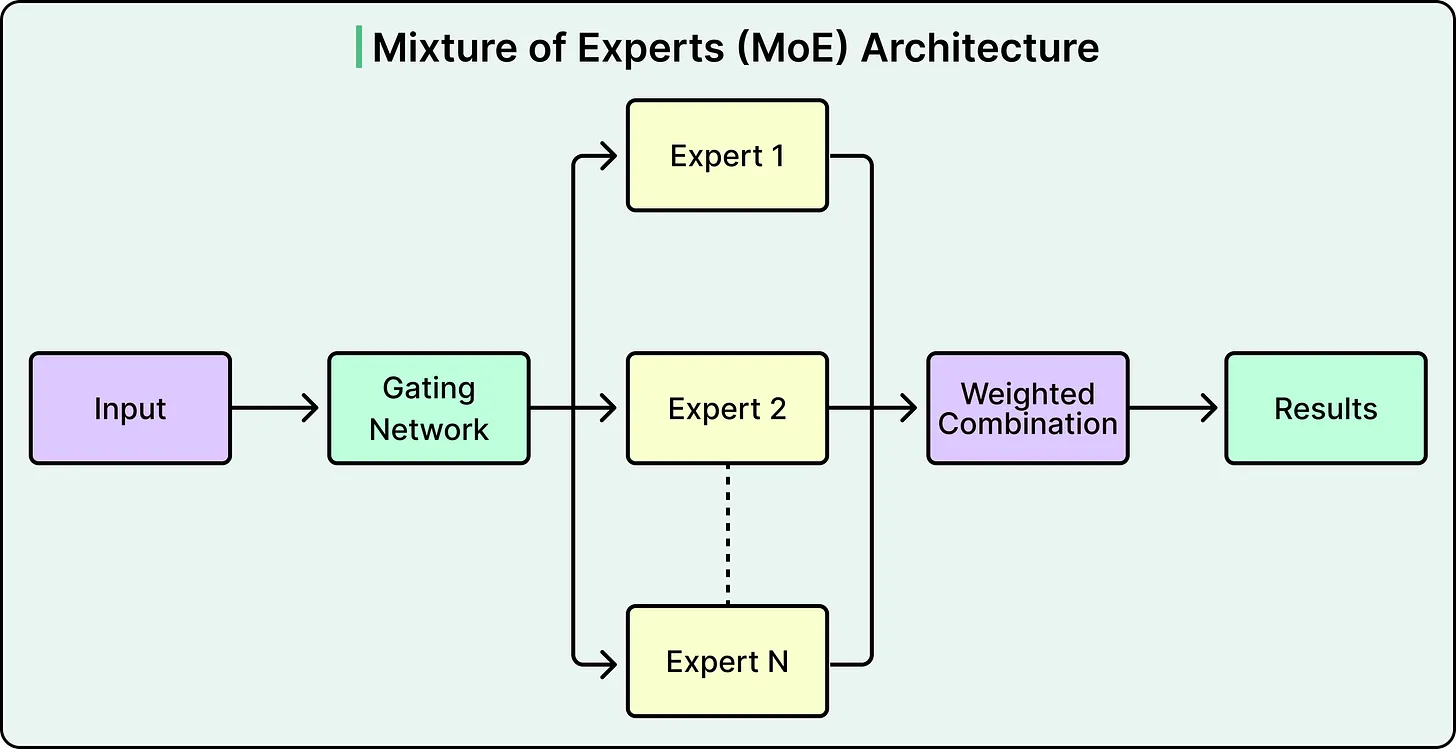
At the core of Roblox’s solution is a transformer-based architecture enhanced by a technique known as Mixture of Experts (MoE). Rather than processing every input through the entire model, MoE selectively activates specialized subnetworks—referred to as “experts”—based on the input language and context.
This design introduces several advantages:
- Efficiency: Only a subset of the model is used per request, reducing computational load
- Specialization: Different experts focus on language groups with similar structures
- Scalability: A single system handles all translation directions
Conceptually, this resembles a routing system where each translation request is directed to the most relevant specialist rather than engaging the entire system.
An additional benefit of this unified approach is cross-lingual learning. Languages with structural similarities—such as Spanish and Portuguese—can reinforce each other during training, improving overall translation quality. The system also demonstrates robustness by:
- Automatically detecting source languages
- Handling mixed-language inputs within a single message
However, these benefits come at a cost. A unified model must be significantly larger to accommodate all language combinations. Roblox’s initial model reached approximately one billion parameters, which introduced new challenges in performance and latency.
Reducing Model Size Without Losing Performance
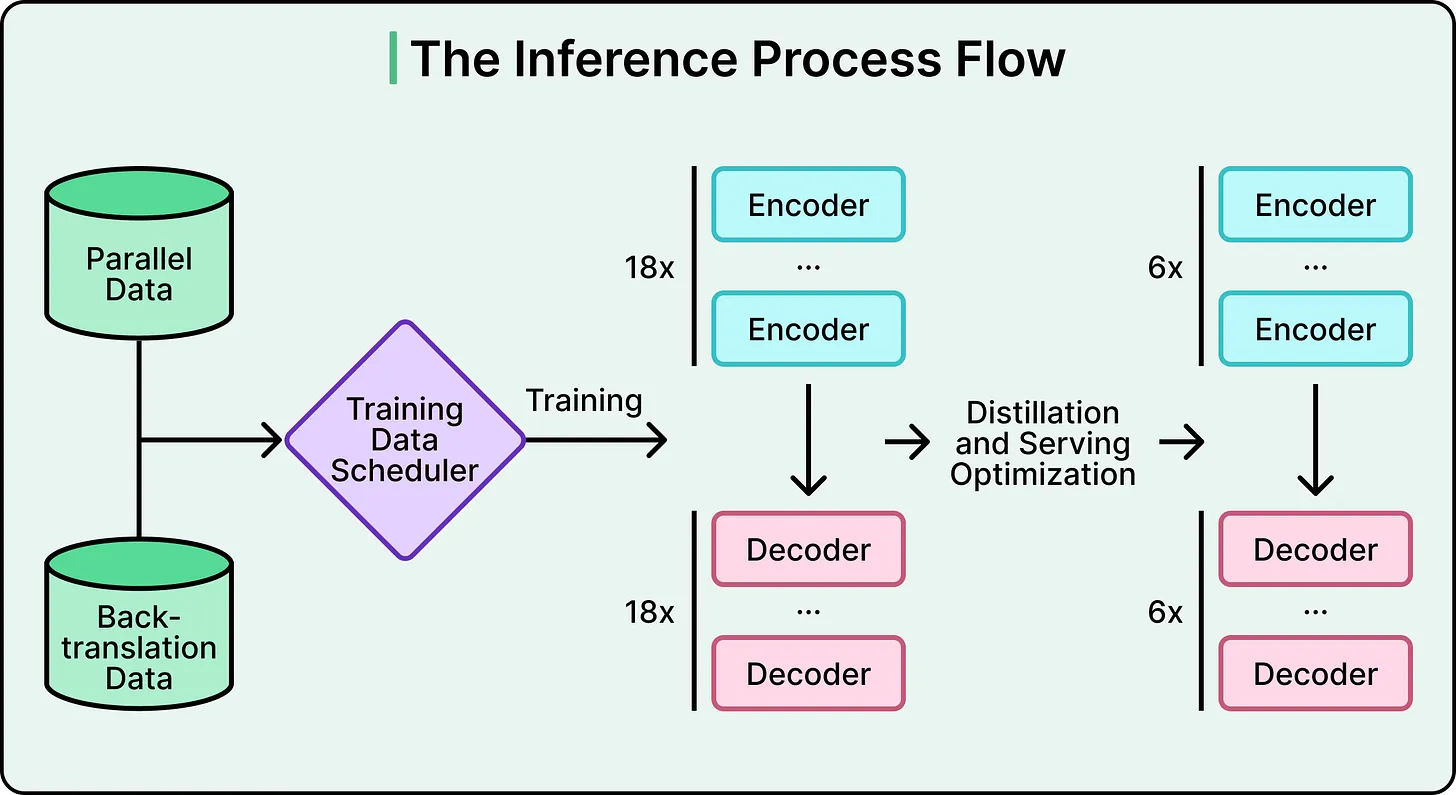
A billion-parameter model may deliver high-quality translations, but it is too slow for real-time conversational use. Roblox needed to reduce model size while preserving accuracy.
They applied knowledge distillation, a process where a smaller “student” model is trained to replicate the behavior of a larger “teacher” model. Importantly, the student learns not only final outputs but also the probability distributions behind them—capturing the teacher’s decision patterns.
Through this process, Roblox reduced the model size to under 650 million parameters.
Additional optimizations included:
- Quantization: Lowering numerical precision to reduce computational cost
- Model compilation: Optimizing execution for specific hardware environments
Despite these improvements, model compression alone was insufficient to meet the strict latency target of ~100 milliseconds. The remaining gains came from infrastructure-level optimizations.
System-Level Optimizations for Speed
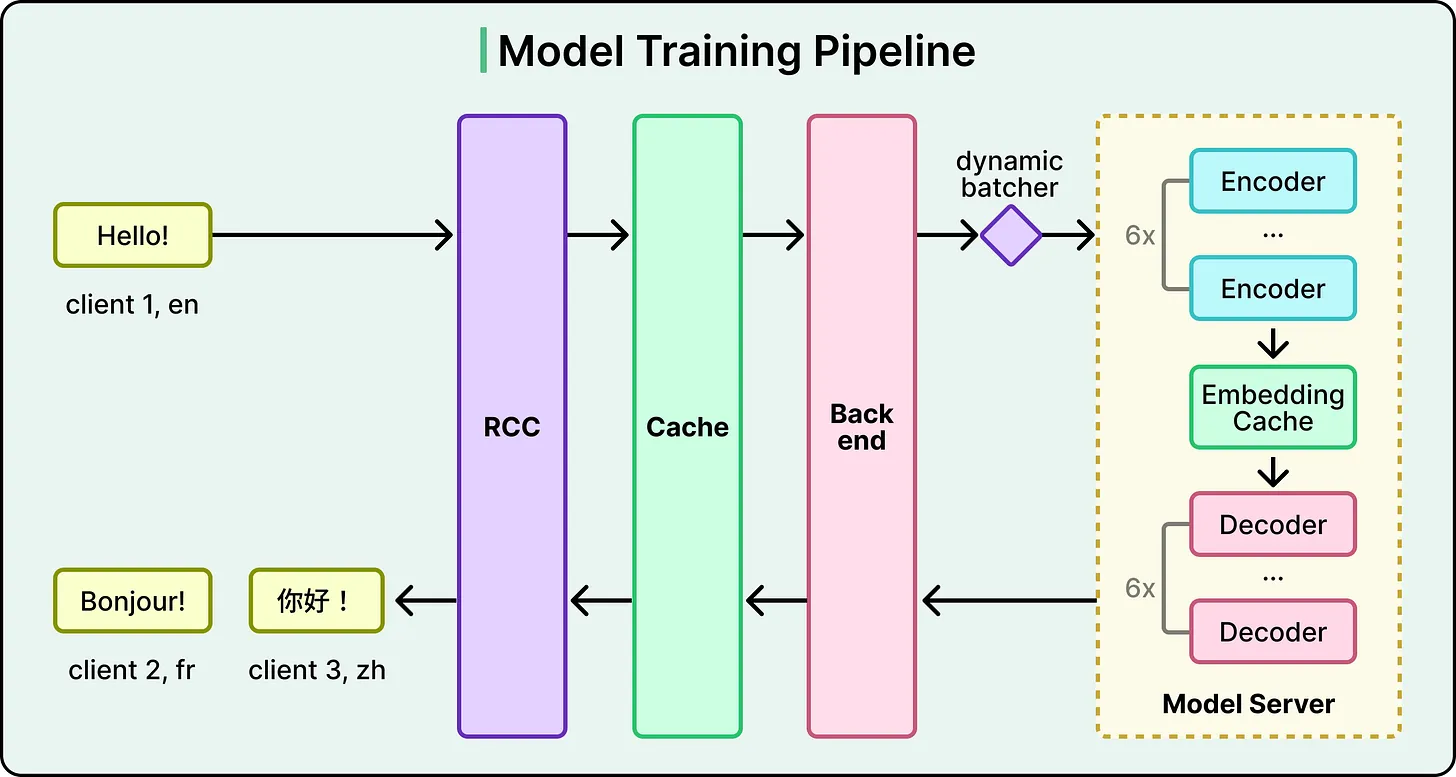
Roblox’s translation pipeline is carefully engineered to eliminate unnecessary computation at every stage.
1. Translation CachingBefore invoking the model, the system checks whether the same translation request has already been processed. If so, the cached result is returned instantly—bypassing inference entirely.
2. Dynamic BatchingIncoming translation requests are grouped together and processed in batches. GPUs are significantly more efficient when handling multiple inputs simultaneously, making batching critical for throughput.
3. Embedding CacheA particularly effective optimization occurs between the encoder and decoder stages. When a single message must be translated into multiple languages, the system encodes it once and reuses the intermediate representation. This avoids redundant computation and reduces latency.
4. Safety and ModerationAfter translation, all outputs pass through Roblox’s trust and safety systems. This ensures that translated content adheres to platform policies before being delivered to users.
Together, these optimizations enable the system to handle over 5,000 translations per second while maintaining near-instant response times.
Measuring Translation Quality Without References

Evaluating translation quality at scale presents a non-trivial problem. Traditional metrics rely on comparing machine output to human-generated reference translations. For 256 language pairs, producing such references continuously is infeasible.
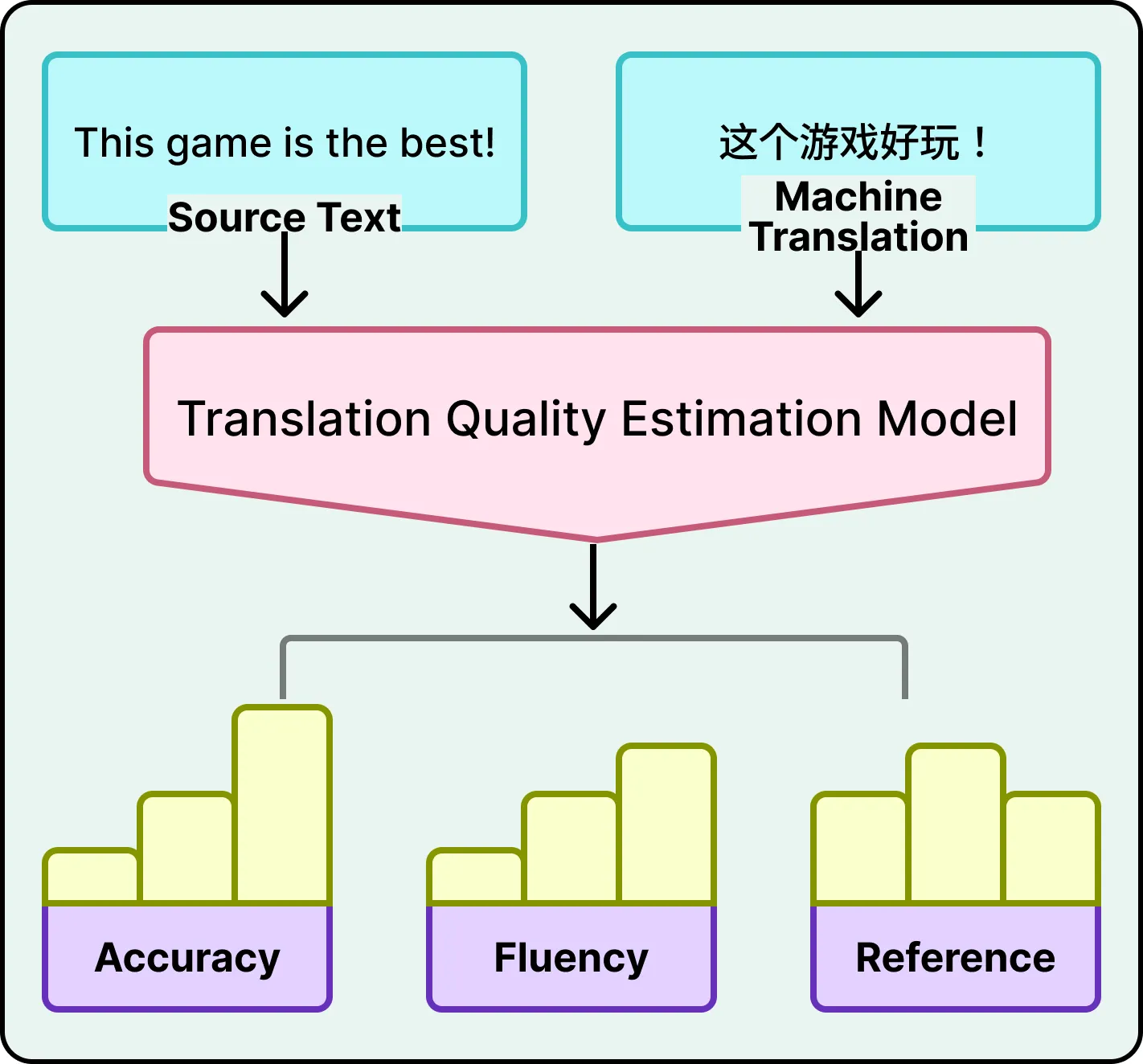
Roblox addressed this by developing a reference-free quality estimation model. This system evaluates translations using only:
- The original source text
- The generated translation
The model assesses multiple dimensions:
- Accuracy: Detecting omissions, additions, or mistranslations
- Fluency: Grammar, spelling, and readability
- Contextual consistency: Alignment with surrounding conversation
Errors are classified by severity (critical, major, minor) and identified at the word level rather than just the sentence level. This granular feedback allows for more precise improvements in model performance.
Handling Low-Resource Language Pairs
Not all language pairs have abundant training data. While English-Spanish translation benefits from vast datasets, pairs like French-Thai are far less represented.
To address this, Roblox employed iterative back-translation:
- Translate text from Language A to Language B
- Translate it back from Language B to Language A
- Compare the result with the original
If the round-trip translation is sufficiently accurate, the intermediate pair is used as synthetic training data. This process is repeated iteratively, gradually expanding the dataset.
However, this approach has limitations. Excessive reliance on synthetic data can degrade model quality, as errors may be reinforced over time.
Adapting to Platform-Specific Language
Generic translation systems often fail to capture domain-specific terminology. Roblox users frequently use unique terms, slang, and abbreviations that do not appear in standard datasets.
To address this, Roblox integrates human-curated translations of platform-specific vocabulary into its training pipeline. This process is ongoing, as user-generated language evolves rapidly.
Trade-offs and Limitations
Roblox’s system demonstrates that achieving real-time, large-scale translation requires compromises:
- Latency vs. Accuracy: Smaller, faster models inevitably lose some fidelity compared to larger ones
- Uneven Performance: Low-resource language pairs remain less accurate
- Operational Complexity: Maintaining a custom translation stack requires continuous investment
- Evaluation Constraints: Reference-free quality models may introduce systematic biases
These trade-offs are not incidental—they are intrinsic to the problem space.
Conclusion
Roblox’s translation system is not defined by a single breakthrough, but by a series of coordinated decisions across model design, infrastructure, and evaluation. By consolidating 256 translation directions into a single MoE-based model, compressing it through distillation, and optimizing the serving pipeline with caching and batching, they achieved a system capable of operating at conversational speed and massive scale.
However, this approach is highly specialized. For most organizations, the cost and complexity of building such a system outweigh the benefits. Off-the-shelf translation APIs remain the more practical choice unless domain-specific accuracy and extreme latency requirements justify a custom solution.
Roblox’s implementation highlights a broader principle in applied AI: performance at scale is rarely about the model alone. It is the integration of architecture, data strategy, and system engineering that ultimately determines success.


