
When OpenAI introduced Codex as a cloud-based coding agent, it marked a shift in how developers interact with AI systems. Rather than functioning as a simple autocomplete engine or code generator, Codex operates as an autonomous agent capable of reasoning, executing tasks, and interacting with development environments.
At first glance, it might seem that the intelligence of Codex lies primarily in its underlying model. In reality, the model is only one part of a much larger system. The true engineering challenge lies in orchestrating how the model interacts with tools, manages context, and operates consistently across different interfaces.
This article explores how Codex works behind the scenes, focusing on three critical layers: the agent loop, context and prompt management, and the multi-interface architecture that enables seamless integration across platforms.
What Codex Actually Does
Codex is designed to assist developers across a wide range of tasks, including:
- Writing new features
- Debugging and fixing issues
- Answering questions about a codebase
- Generating and refining pull requests
Each task is executed within an isolated environment that contains the relevant codebase. This isolation ensures safety, reproducibility, and the ability to run multiple tasks in parallel.
However, the visible output—code suggestions or fixes—is only the final step in a much more complex process.
The Agent Loop: The Core Execution Engine
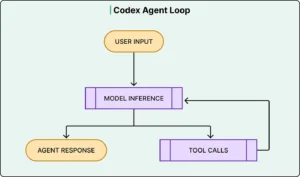
At the heart of Codex is what can be described as an agent loop. This loop defines how the system processes a request and iteratively works toward a solution.
The process begins when a user submits a task. The system constructs a prompt and sends it to the model. Instead of always returning a final answer, the model often responds with an action—such as executing a command or retrieving additional information.
This leads to a cycle:
- The model generates a response (often a tool instruction)
- The system executes the instruction (e.g., run tests, read files)
- The results are appended to the context
- The updated context is sent back to the model
- The cycle repeats until a final result is produced
This iterative process allows Codex to behave more like an active collaborator than a passive responder.
For example, a request to fix a bug may involve:
- Inspecting relevant files
- Running existing test suites
- Identifying failing cases
- Modifying code
- Re-running tests to verify the fix
The model handles reasoning at each step, while the surrounding system—often referred to as the harness—manages execution, permissions, and state transitions.
Tools and Execution Capabilities
Codex’s effectiveness depends heavily on its ability to interact with tools. These include:
- File system access (reading and editing code)
- Shell command execution
- Test runners and linters
- Type checkers and build systems
The agent does not operate in isolation; it actively engages with the development environment. This capability transforms it from a text generator into a functional problem-solving system.
However, tool execution introduces risk. Commands may alter code or system state, so Codex incorporates permission controls and approval mechanisms to ensure safe operation.
Prompt Construction and Context Management
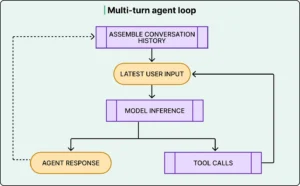
One of the most complex aspects of Codex is how it constructs and manages prompts.
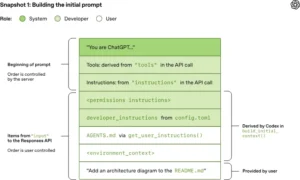
When a user submits a request, that input is only a small part of the total context sent to the model. The full prompt typically includes:
- System-level instructions
- Developer-defined configurations
- Tool definitions
- Environment details (e.g., directory structure, shell state)
- Project-specific guidelines
- Conversation history, including previous actions and outputs
Each layer serves a distinct purpose and is assigned a role that determines its priority in influencing the model’s behavior.
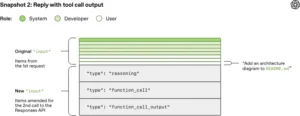
The Challenge of Growing Context
As the agent loop progresses, the context grows rapidly. Every action taken by the system—such as running a command or editing a file—produces output that must be included in subsequent prompts.
Additionally, each new interaction includes the full history of previous steps. This creates a compounding effect where the size of the prompt increases significantly over time.
This design is intentional. By keeping each request self-contained, Codex avoids relying on server-side memory. This approach supports stricter privacy requirements, including scenarios where data retention must be minimized or eliminated.
However, it introduces two major challenges:
- Increased data transfer
- Higher computational cost
Mitigating Context Explosion
To manage this growth, Codex employs several strategies:
Prompt Caching
Since new prompts typically append data to existing context, earlier portions remain unchanged. This allows the system to reuse previous computations, reducing the effective cost of repeated processing.
Context Compaction
When the prompt approaches the model’s maximum context limit, Codex compresses the conversation history. Instead of retaining every detail, it replaces earlier interactions with a condensed representation that preserves essential information.
This compaction process is critical for maintaining long-running sessions without exceeding system limits.
Project-Specific Context with Configuration Files
Codex introduces a mechanism for embedding project knowledge directly into the repository through configuration files. These files define:
- Coding standards
- Preferred workflows
- Test commands
- Repository structure
By placing this information alongside the codebase, developers can guide the agent’s behavior without modifying the underlying system.
This design choice reflects an important principle: context should be close to where it is used, rather than hardcoded into the system.
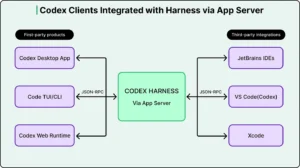
Multi-Interface Architecture: One Agent, Many Surfaces
Codex is not confined to a single interface. It operates across:
- Command-line tools
- Integrated Development Environments (IDEs)
- Web-based applications
- Desktop environments
Supporting all these environments with a single agent requires a unified architecture.
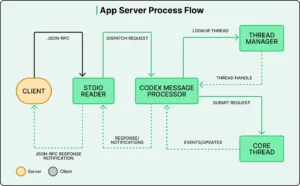
The App Server: A Centralized Core
To achieve this, OpenAI built a centralized component known as the App Server. This server encapsulates the core logic of Codex, including:
- The agent loop
- Tool execution
- Context management
- Authentication and configuration
Clients—such as IDE extensions or web applications—communicate with the App Server using a standardized protocol.
This architecture enables:
- Consistent behavior across platforms
- Easier updates and maintenance
- Separation between core logic and user interface
Bidirectional Communication and User Control
A key feature of this system is its bidirectional communication model.
Not only can the client send requests to the server, but the server can also:
- Request user approval before executing actions
- Provide real-time progress updates
- Stream intermediate results
This allows Codex to balance autonomy with user oversight. For example, the agent may pause mid-task and request permission before running a potentially impactful command.
Cloud Execution and Persistence
In cloud-based environments, Codex runs tasks inside isolated containers preloaded with the user’s repository. This setup provides several advantages:
- Tasks continue running even if the user disconnects
- Work can be parallelized across multiple instances
- Results can be monitored in real time
This model shifts the interaction paradigm from immediate responses to asynchronous collaboration.
Practical Implications for Developers
Understanding how Codex works reveals several practical insights:
- Clear task definitions improve results: The agent loop performs best when objectives are well-scoped
- Project context matters: Providing structured guidance through configuration files enhances output quality
- Session management is important: Long conversations may degrade due to context limits, making fresh sessions more effective for new tasks
Additionally, Codex is particularly effective for repetitive and structured tasks, such as refactoring, test generation, and debugging workflows.
Limitations and Trade-offs
Despite its capabilities, Codex has inherent constraints:
- It relies on iterative loops, which can increase latency
- Context management introduces complexity and potential degradation over time
- Full autonomy is limited by the need for user approvals and safety mechanisms
- Certain tasks, especially those requiring visual understanding, remain challenging
These limitations highlight that Codex is not a fully autonomous developer but rather a sophisticated assistant.
Conclusion
OpenAI Codex represents a shift from static AI tools to dynamic, agent-based systems. While the underlying model provides reasoning capabilities, the true innovation lies in the orchestration layer that manages context, tools, and interactions.
The agent loop enables iterative problem-solving, prompt management ensures contextual awareness, and the multi-interface architecture allows the system to operate seamlessly across environments.
Ultimately, Codex demonstrates that building effective AI systems is not just about improving models—it is about designing the systems around them. The intelligence of the agent emerges from the integration of reasoning, execution, and context management, rather than any single component alone.

